0.8 ms
p95 SLO held under dynamic trace
Dynamic CPU-allocation controller for Kubernetes that holds memcached's tail-latency SLO while running PARSEC batch jobs on freed cores.
ETH Zürich, Systems Group (Cloud Computing Architecture course) · Feb 2025 – Jun 2025
Cloud workloads mix latency-critical services like memcached (1 ms p95 at 30K QPS) with throughput-oriented batch jobs. They have to share hardware to keep utilisation up, but cache contention and memory-bandwidth pressure degrade tail latency the moment they're co-located. Static partitioning protects the SLO at the cost of cores left idle whenever the latency-critical service is quiet.
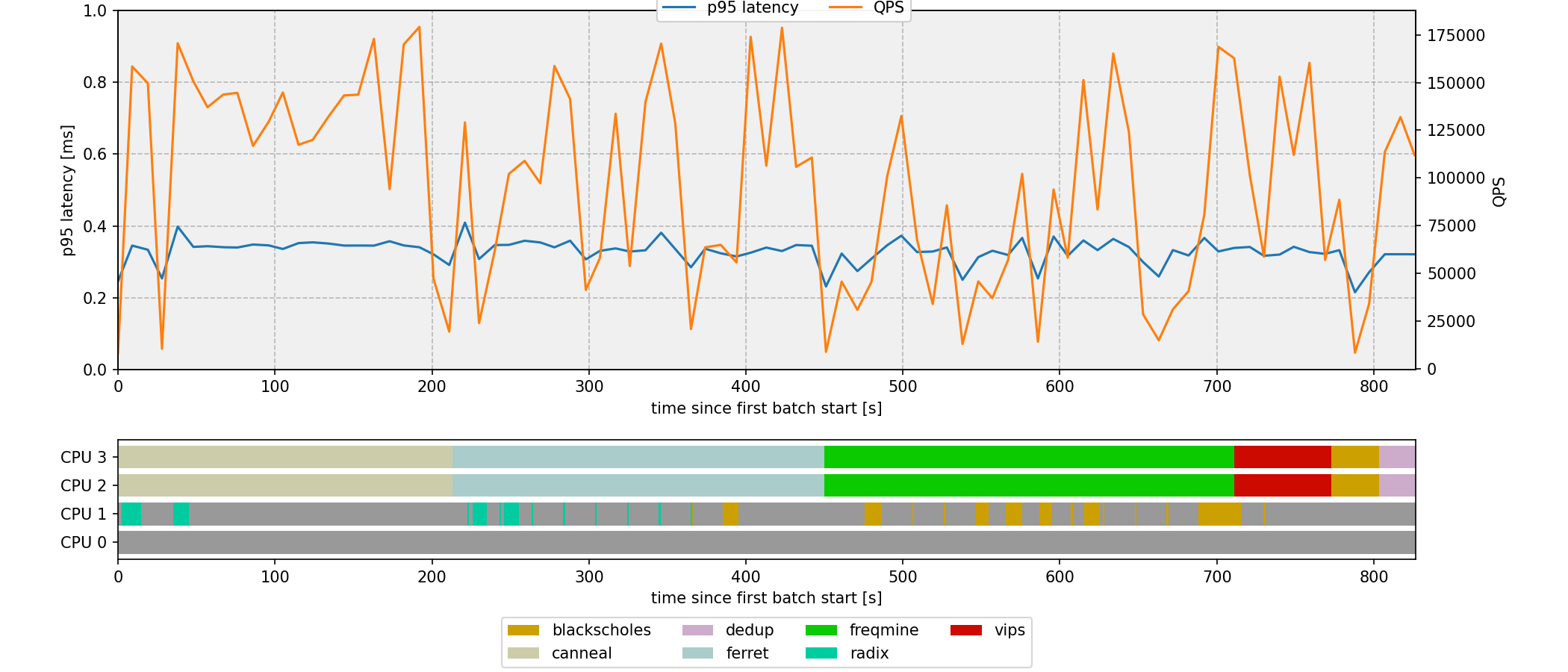
The project tackles this in four parts. First, characterise memcached and seven PARSEC batch workloads under explicit iBench interference. Then co-schedule them on a heterogeneous Kubernetes cluster. Finally, close the loop with a Python controller that reallocates CPU cores at runtime via Docker. The 0.8 ms p95 SLO holds under a dynamic 5K to 180K QPS trace while every batch job runs to completion.
Built the per-job interference matrix that drives every scheduling decision later in the project.
Designed a placement policy that holds the 1 ms / 30K QPS SLO while finishing all seven batch jobs as fast as possible.
Closed-loop scheduler on a single 4-core VM that watches memcached load and reallocates cores at runtime under a dynamic 5K to 180K QPS trace.
A Kubernetes cluster on a public cloud for Parts 1 to 3, and a single 4-core VM with a Python control loop for Part 4.
Key technical decisions
0.8 ms
p95 SLO held under dynamic trace
0 %
SLO violations across 3 runs (10 s interval)
158 s
Part 3 mean makespan (1 ms / 30K QPS)
809 s
Part 4 mean makespan (0.8 ms / 180K QPS dynamic)
Top 6
In-course ranking