~7
FLOPS/cycle (Linear & GroupNorm, compute-bound)
Hand-optimised C99 + AVX2 implementation of geometric-algebra neural-network layers, benchmarked to a roofline and bit-perfect against the reference PyTorch implementation of Clifford Neural Networks.
ETH Zürich, Advanced Computing Lab · Feb 2025 – Jun 2025
Clifford Neural Networks (Brandstetter et al., Ruhe et al.) represent data, weights, and transformations as multivectors instead of scalars. Each multivector is a linear combination of basis blades (scalars, vectors, bivectors, higher-grade primitives), which makes the model naturally good at PDE modelling and physical simulation. The cost is brutal. Each feature has 2ᵈ components, the geometric product creates dense cross-blade coupling, and the reference PyTorch implementation of these layers is far too slow for real-time or large-batch inference.
We started from the open-source CliffordLayers reference and rewrote the three bottleneck layers (Clifford Linear, Multivector SLU, Clifford Group Normalisation) in hand-tuned C99 with AVX2 intrinsics. The kernels drop into the existing Python codebase via ctypes and are checked bit-perfect against the reference PyTorch implementation of these layers on every commit.
Each layer was translated from the reference PyTorch implementation of Clifford Neural Networks into hand-tuned C99 and exposed back to Python through ctypes so the existing training and inference scripts run unchanged.
Progressive optimisations across all three layers, validated bit-perfect after every change.
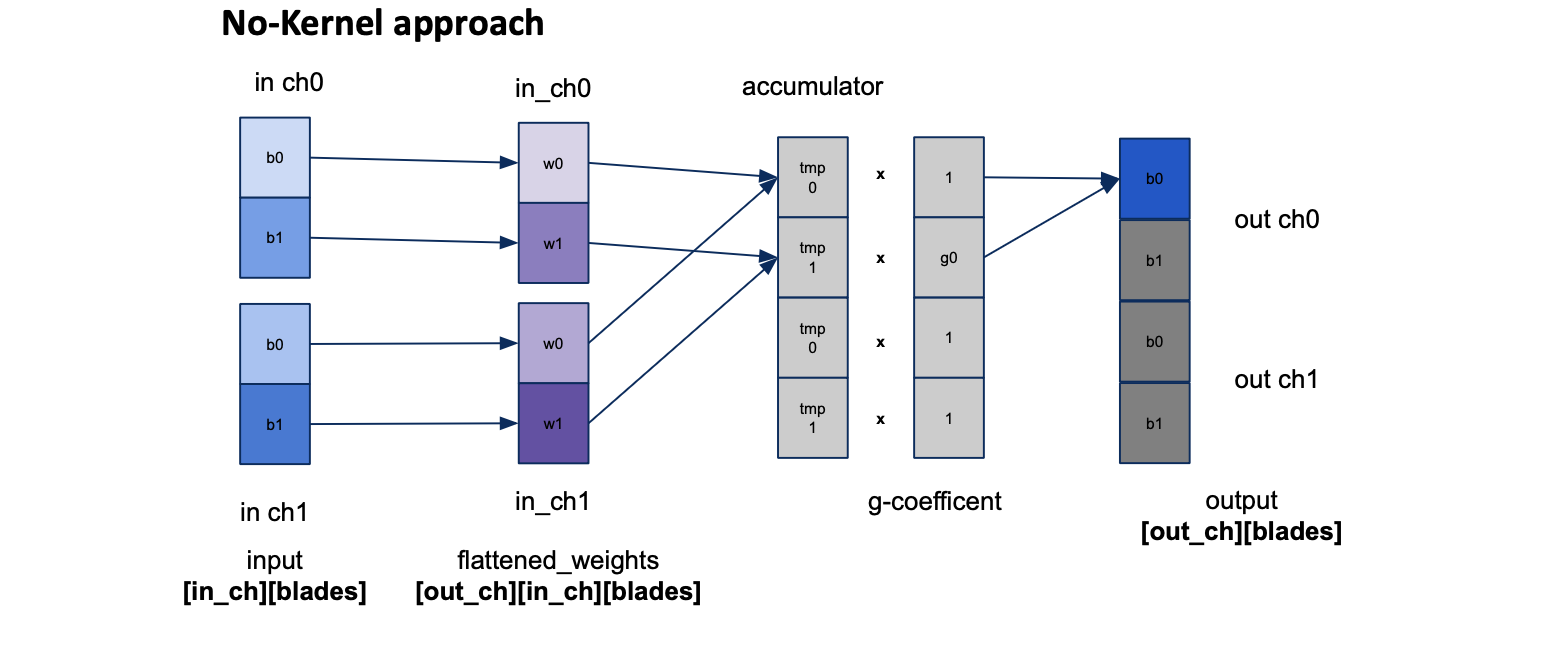
A second path for the Linear layer that skips constructing the kernel matrix, plus a verification harness that gates every change.
Three layers, all rewritten in C with vector intrinsics, cycle-counted layer-by-layer, and validated bit-perfect against the reference.
Key technical decisions
~7
FLOPS/cycle (Linear & GroupNorm, compute-bound)
5.5×
AVX2 speedup over baseline (Linear)
<1e-6
Bit-perfect parity vs reference PyTorch CliffordLayers
SLU ceiling
~0.9 FLOPS/cycle, gather-bound. Load ports are saturated, not compute.