32.86 %
Forecasting MAPE (4-day, Germany, retrained, down from 56.78 %)
Full-stack dashboard estimating and forecasting the carbon footprint of computational workloads across European regions.
University of Groningen · Oct 2023 – Aug 2024
Computing's carbon footprint comes down to three things. How much power the hardware actually draws, how dirty the local grid is at that moment, and how long the work runs. Server emissions swing sharply with all three, but most online estimators substitute generic CPU TDP for real measured power and skip the temporal mix entirely. The result is that organisations have almost no honest visibility into when or where to schedule workloads to keep impact down.
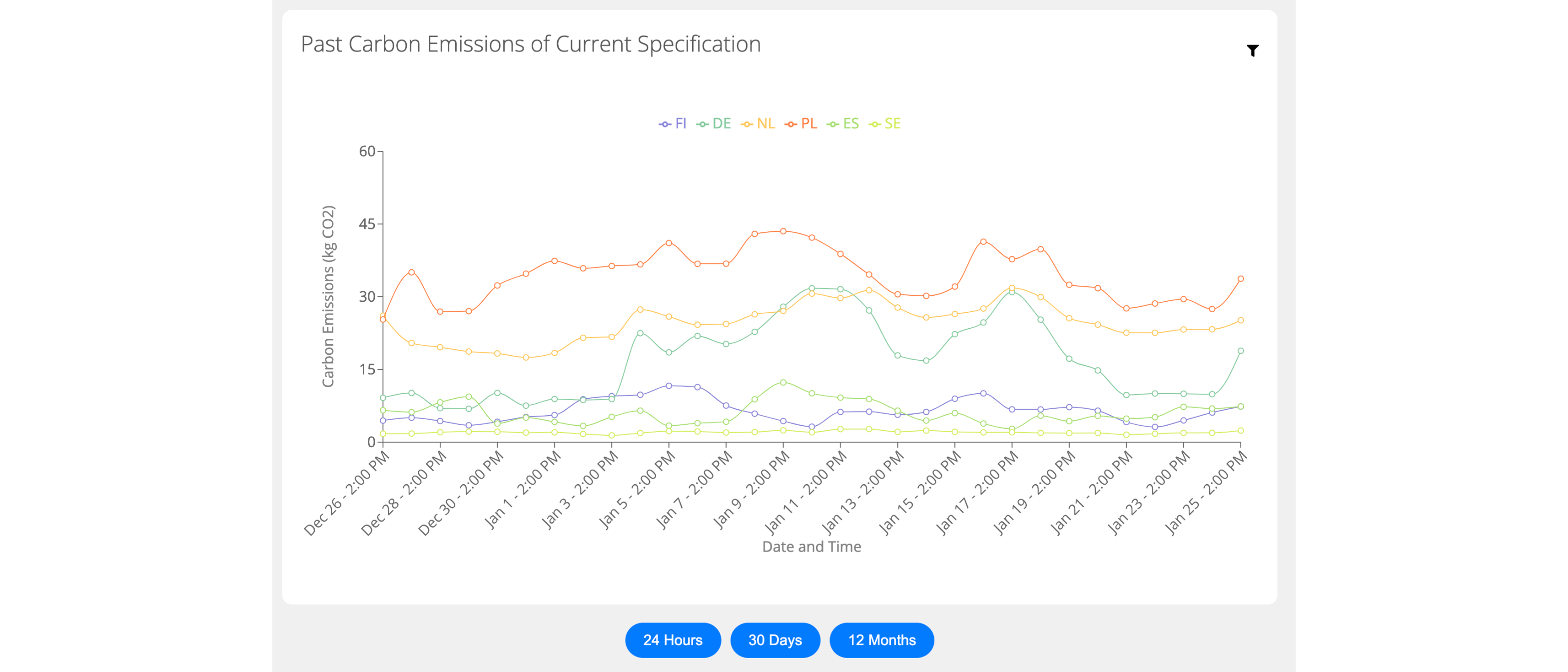
The dashboard combines all three signals. Under the hood: live ENTSO-E generation data, SPECpower ssj2008 benchmark measurements per CPU, and a 96-hour CarbonCast forecast that pairs per-source ANNs with a CNN-LSTM aggregator. Users pick a CPU, load level, runtime, PUE, and start time, then see per-region totals alongside 30-day and 12-month patterns that expose seasonal and time-of-day effects.
Four years of hourly per-source generation data per region from ENTSO-E, distilled into hourly Carbon Intensity values.
Uses SPECpower ssj2008 measured power instead of generic CPU TDP, so the numbers reflect what the hardware actually draws.
Two-tier deep-learning pipeline that forecasts CI up to four days ahead, so users can schedule workloads at the cleanest hours.
Next.js + React + MUI front-end with five views: past, present, future, and the estimator.
Three-tier web stack with two ML pipelines on the data side. Frontend, backend, and database run as separate services; CarbonCast and the data-cleaning scripts run offline.
Key technical decisions
32.86 %
Forecasting MAPE (4-day, Germany, retrained, down from 56.78 %)
82.64
Forecasting RMSE (down from 118.31 before retraining)
6
European regions in the dashboard
96 h
Carbon-intensity forecast horizon
4 yr
Historical ENTSO-E coverage (2020-2024)